
Temporal Modular Networks for Retrieving Complex Compositional Activities in Videos
Bingbin Liu, Serena Yeung, Edward Chou, De-An Huang, Li Fei-Fei, Juan-Carlos Niebles
Abstract
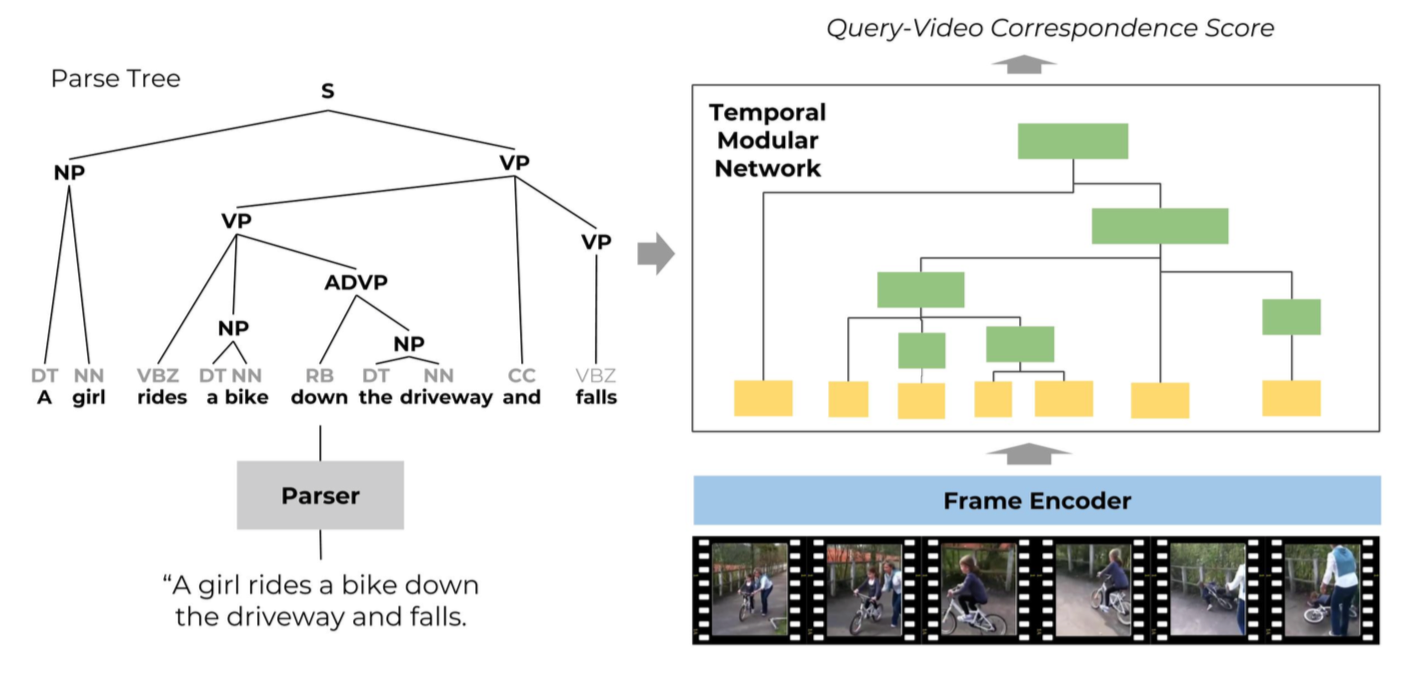
A major challenge in computer vision is scaling activity understanding to the long tail of complex activities without requiring collecting large quantities of data for new actions. The task of video retrieval using natural language descriptions seeks to address this through rich, unconstrained supervision about complex activities. However, while this formulation offers hope of leveraging underlying compositional structure in activity descriptions, existing approaches typically do not explicitly model compositional reasoning. In this work, we introduce an approach for explicitly and dynamically reasoning about compositional natural language descriptions of activity in videos. We take a modular neural network approach that, given a natural language query, extracts the semantic structure to assemble a compositional neural network layout and corresponding network modules. We show that this approach is able to achieve state-of-the-art results on the DiDeMo video retrieval dataset.